Five student projects from MIT’s 4.043 / 4.044 Interaction Intelligence course were accepted at NeurIPS, showing how AI transforms creativity, education, and interaction in unexpected ways.
By Adelaide Zollinger
Jan 7, 2025
Imagine a boombox that tracks your every move and suggests music to match your personal dance style. That’s the idea behind “Be the Beat,” one of several projects from MIT’s 4.043 / 4.044 Interaction Intelligence course, taught by Marcelo Coelho in the Department of Architecture, that were presented at the 38th annual NeurIPS (Neural Information Processing Systems) conference in December 2024. With over 16,000 attendees converging in Vancouver, NeurIPS is a competitive and prestigious conference dedicated to research and science in the field of artificial intelligence (AI) and machine learning (ML), and a premier venue for showcasing cutting-edge developments.
Next offered in spring 2025, the course investigates the emerging field of Large Language Objects (LLO), and how artifical intelligence can be extended into the physical world. While “Be the Beat” transforms the creative possibilities of dance, other student submissions span disciplines such as music, storytelling, critical thinking, and memory, creating generative experiences and new forms of human computer interaction. Taken together, these projects illustrate a broader vision for AI: one that goes beyond automation to catalyze creativity, reshape education, and reimagine social interactions.
Ethan Chang (Mechanical Engineering and Design, ‘25)
Zhixing Chen (Mechanical Engineering and Music, ‘25)
“Be the Beat” is an AI-powered boombox that suggests music from a dancer's movement. Dance has traditionally been guided by music throughout history and across cultures, yet the concept of dancing to create music is rarely explored.
“Be the Beat” creates a space for human-AI collaboration on freestyle dance, empowering dancers to rethink the traditional dynamic between dance and music. It uses PoseNet to describe movements for a large language model, enabling it to analyze dance style and query APIs to find music with similar style, energy, and tempo. Dancers interacting with the boombox reported having more control over artistic expression and described the boombox as a novel approach to discovering dance genres and choreographing creatively.
Q: What inspired you to work on this project?
As dancers, freestyle movement is at the core of who we are. For both of us, dance is a creative outlet and a language that is hard to turn to words. There are moments when we feel a certain vibe or energy that’s hard to articulate, but through dance, we connect with the world and express what words cannot. Our goal is to introduce technology that empowers people to take control of their expressive journeys, bridging the gap between emotion and communication through movement.
Q: How do you see your project contributing to the fields of AI and machine learning?
AI has been facilitating humans to develop creative work like art, music, texts, or even videos. However, the concept of co-creation is rare. Be the Beat empowers human creativity rather than simply creating on behalf of humans and makes the human-computer experience non-intruding and unique.
Q: What was the most challenging part of the process for you?
The most challenging aspect of our process lies in designing a device that accurately captures the intricate relationship between dance and music while providing a seamless user experience. The nuances of dance movements and music are often complex, even for humans to fully comprehend. Empirically evaluating the device's performance in achieving this goal adds another layer of difficulty.
Mrinalini Singha (SMACT ‘24)
Haoheng Tang (Harvard GSD ‘24)
“A Mystery for You” is an educational game designed to cultivate critical thinking and fact-checking skills in young learners. The game leverages a large language model (LLM) and a tangible interface to create an immersive investigative experience. Players act as citizen fact-checkers, responding to AI-generated ‘news alerts’ printed by the game interface. By inserting cartridge combinations to prompt follow-up ‘news updates,’ they navigate ambiguous scenarios, analyze evidence, and weigh conflicting information to make informed decisions.
This Human Computer Interaction (HCI) experience challenges our news-consumption habits by eliminating touchscreen interfaces, replacing perpetual scrolling and skim-reading with a haptically rich analog device. By combining the affordances of slow media with new generative media, the game promotes thoughtful, embodied interactions while equipping players to better understand and challenge today’s polarized media landscape, where misinformation and manipulative narratives thrive.
Q: What inspired you to work on this project?
In an age of rampant misinformation and AI-generated media, fact-checking, media literacy, and an investigative mindset are essential life skills. Working with a fact-checking organization in India, we saw how a lack of media literacy left individuals vulnerable to manipulative narratives, a problem worsened by generative AI.
This raised a pivotal question: Could AI, often used to spread misinformation, be repurposed to combat it? We saw an opportunity in designing situational puzzles that encourage lateral thinking and problem-solving. Conversational AI agents, such as large language models, excel at building sequential narratives by dynamically generating content that adapts to user input. By leveraging an OpenAI API’s ability to generate dynamic, adaptive narratives, we created A Mystery for You—a game that entertains while equipping players to critically navigate today’s polarized media landscape.
Q: How do you see your project contributing to the fields of AI and machine learning?
A Mystery for You contributes to AI and machine learning by integrating generative models with tangible, analog-inspired interfaces to foster active learning. Its A+B cartridge system uses physicality to create narrative structure and guardrails, unlike typical LLM-driven AI NPCs, enabling safe, meaningful gameplay. By embracing ambiguity, it simulates real-world misinformation, fostering critical analysis while addressing AI biases and ethical concerns. Promoting slow media, the game encourages reflective interactions and serves as a diagnostic tool for uncovering biases in AI and human decision-making. This highlights the potential of AI and tangible media in fostering immersive, critical learning experiences across fields like media literacy, climate science and ethics.
Q: What was the most challenging part of the process for you?
The biggest challenge was balancing AI’s generative flexibility with the need for structured gameplay. While LLMs excel at open-ended narratives, their outputs can be unwieldy without clear boundaries. The A+B cartridge system acted as a physical guardrail, ensuring scenarios remained engaging, coherent, and educational. We also needed a screen-free interface for thoughtful interaction. The receipt printer’s slow-response medium contrasted with the fast-paced scrolling of modern touchscreens, fostering mindfulness and intentional engagement.
Another significant challenge was ensuring logical, consistent puzzle content. This required meticulous prompt engineering and rigorous playtesting with the OpenAI API to craft coherent clues and sequential flows while addressing biases. Content moderation policies also influenced scenario generation, underscoring the need for further research into their impact on gameplay.
Keunwook Kim (Harvard GSD ‘25 / MIT Media Lab TA)
Memorscope is a device that creates collective memories by merging the deeply human experience of face-to-face interaction with advanced AI technologies. Inspired by how we use microscopes and telescopes to examine and uncover hidden and invisible details, Memorscope allows two users to “look into” each other’s faces, using this intimate interaction as a gateway to the creation and exploration of their shared memories.
The device leverages AI models such as OpenAI and Midjourney, introducing different aesthetic and emotional interpretations, which results in a dynamic and collective memory space. This space transcends the limitations of traditional shared albums, offering a fluid, interactive environment where memories are not just static snapshots but living, evolving narratives, shaped by the ongoing relationship between users.
Q: What inspired you to work on this project?
My obsession with taking photos — I have 190,923 photos and videos in my iCloud photo reels — my poor memory, and my fascination with technology, specifically my curiosity about the future of AI interfaces, were the key inspirations for this project.
Q: How do you see your project contributing to the fields of AI and machine learning?
I believe this project is an exploration of how we can reinvent the way humans remember. AI and machine learning are brilliant tools, but they are just ingredients for technologies we have yet to fully develop. I want to keep working on creating new tools that leverage AI and machine learning in meaningful ways.
Q: What was the most challenging part of the process for you?
The most challenging part was that the GenAI model people loved most (Midjourney) didn’t have an API. I had to manually collect and arrange the photos from participants, input them into the model to ‘blend’ them, and then present the results manually. However, this process also allowed me to engage more deeply with the audience. Ultimately, the conversations I had with them became the final touches that completed the work.
Xiying (Aria) Bao (Harvard GSD ‘23)
Yubo Zhao (Harvard GSD ‘23)
“Narratron” is an interactive projector that co-creates and co-performs children's stories through shadow puppetry using Large Language Models. Users can press the shutter to “capture” protagonists they want to be in the story, and it takes hand shadows (such as animal shapes) as input for the main characters. The system then develops the story plot as new shadow characters are introduced. The story appears through a projector as a backdrop for shadow puppetry while being narrated through a speaker as users turn a crank to “play” in real-time. By combining visual, auditory, and bodily interactions in one system, the project aims to spark creativity in shadow play storytelling and enable multi-modal human-AI collaboration.
Q: What inspired you to work on this project?
I (Yubo) come from Shaanxi Province, China, where Chinese Pi Ying Xi — or hand shadow play — originated. Like Greek Karagiozis or even the simplest childhood fun of mimicking animals through shadows, hand shadow play is an ancient, transcultural storytelling practice that is deeply rooted in human instincts and the ability for imagination. We found this interaction incredibly intriguing as it stimulates creativity in childhood, and were curious about how this practice could be augmented even more with the power of generative AI.
Q: How do you see your project contributing to the fields of AI and machine learning?
‘Narratron’ integrates AI as a ‘fairytale copilot,’ embedding intelligence into the collective efforts of hands, eyes, and brains. Its multimodal nature combines visual, auditory, tactile, and textual I/O, seamlessly blending with AI technologies like LLM, image classifiers, speech synthesizers, and diffusion models. It envisions how AI can be naturally fused into instinctive practices and interactions. ‘Narratron’ bridges the digital and physical, connecting ancient traditions of hand shadow puppetry with the future of interactive storytelling.
Q: What was the most challenging part of the process for you?
It was challenging to ensure that the output content was meaningful and appropriate for children, our intended target audience. At the time Narratron was built, there was no LLM specifically trained for children-friendly content generation, nor was the image generator optimized for this purpose. We encountered issues when the story used inappropriate language or adult-oriented vocabulary, contained plots infused with negativity and violence, or presented horror images that were completely opposite to a fairytale atmosphere. We addressed these challenges by testing various prompt engineering strategies and creating LoRA with different training datasets, and we ultimately were able to achieve stable and desired results.
Karyn Nakamura (BSAD ‘24)
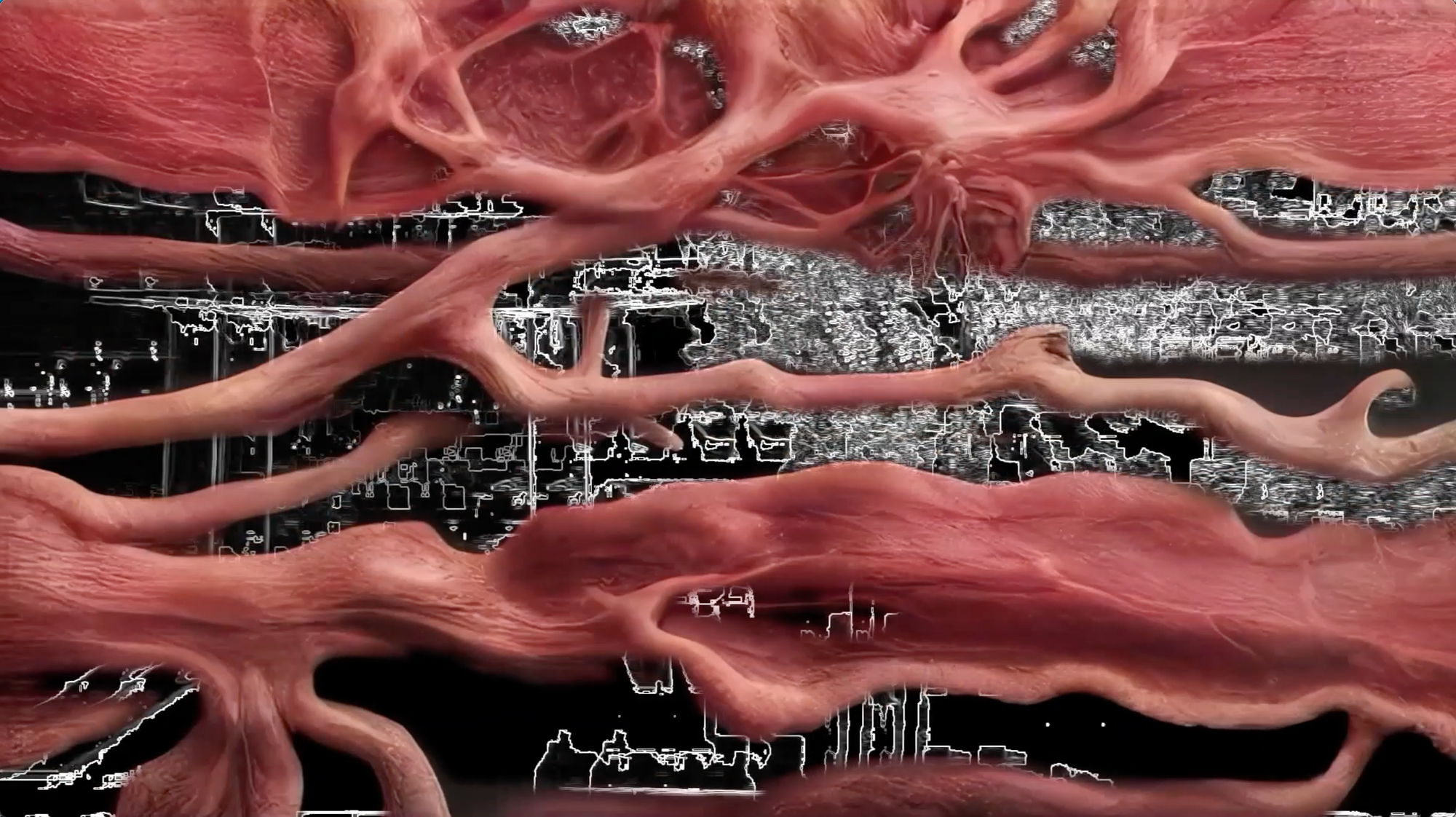
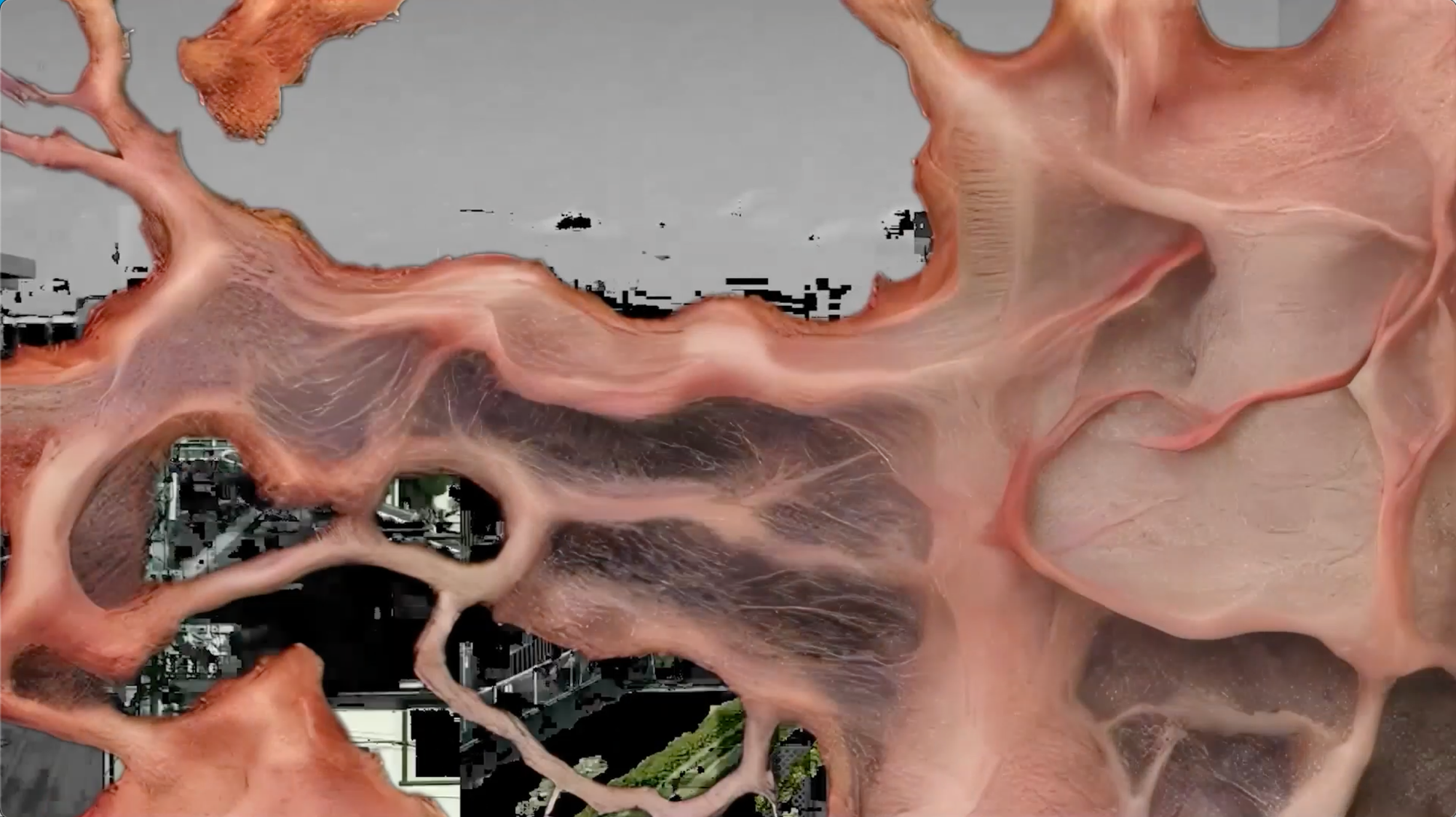
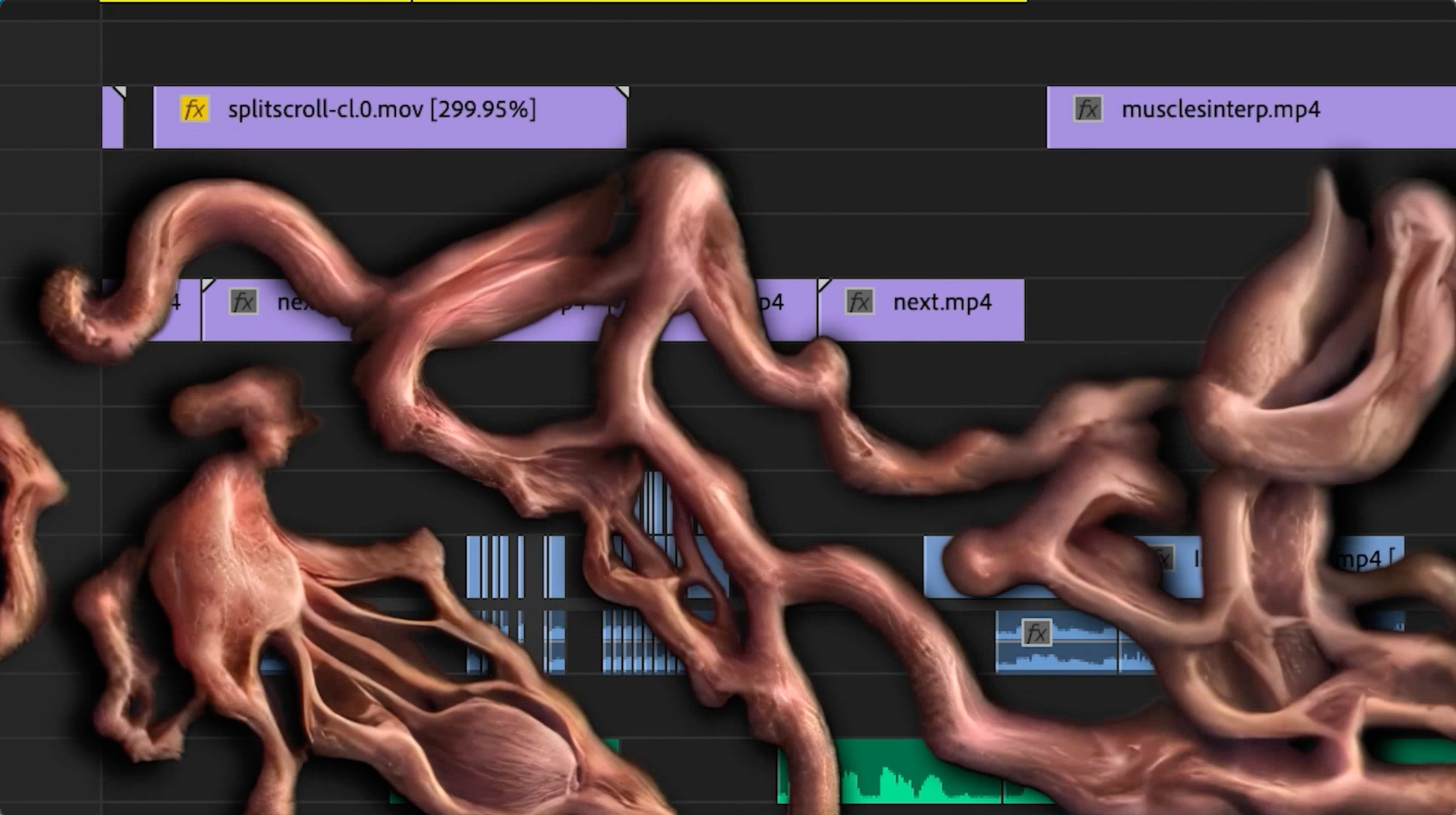
Perfect Syntax is a video art piece examining the syntactic logic behind motion and video. Using AI to manipulate video fragments, the project explores how the fluidity of motion and time can be simulated and reconstructed by machines. Drawing inspiration from both philosophical inquiry and artistic practice, Nakamura's work interrogates the relationship between perception, technology, and the movement that shapes our experience of the world. By reimagining video through computational processes, Nakamura investigates the complexities of how machines understand and represent the passage of time and motion.
Q: What inspired you to work on this project?
In early January this year, I was back home in Japan on a train in rural Osaka to visit my grandparents. Staring out the window at the peaceful landscapes passing by rhythmically, I was thinking, what is video? How does motion even work? How is it that we see a sequence of frames, flashing images one after another, and weave continuous logic in between? We seem to take our ability to sequence information in the ever-flowing stream of time so casually as this metaphysical background of our experience of life.
Q: How do you see your project contributing to the fields of AI and machine learning?
Perfect Syntax fantasizes about a logic building system, imagining it as an artificial ‘video muscle.’ The video begins with footage of a train window and a diary-like description of an ordinary day of activities. As it is repeated, it becomes increasingly distorted, changing the progression of events, circling back on itself, and dissolving in and out of image, noise, and abstract forms. At least currently, it remains a challenge to simulate (models struggle with occlusion — understanding context beyond the frame like scenes that move through a train window). But eventually, when a synthetic process can put together the syntactic logic of the world, what does that mean and what would it look like?
Q: What was the most challenging part of the process for you?
Creating this video was very time consuming. I developed a workflow for generating smooth Image to Image video using Stable Diffusion by processing the original train footage to generate specific latents from it. By doing this I was able to have precise control of motion — in other words change in one frame to the next by guiding the noise (where change would occur) like a stop motion video.
For more design + AI-related content, check out the replay from Design Miami’s panel discussion featuring MIT faculty: Beyond Human, Artificial Intelligence and the Future of Design.

Sep 6, 2024

Dec 12, 2024

Oct 10, 2023