Merging Design and Computer Science in Creative Ways

Apr 9, 2025
Speech-to-Reality System combines 3D Generative AI and robotic assembly to create objects on demand.
By Denise Brehm
Nov 20, 2025
Generative AI and robotics are moving us ever closer to the day when we can ask for an object and have it created within a few minutes. In fact, MIT researchers have developed a Speech-to-Reality system, an AI-driven workflow that allows them to provide input to a robotic arm and “speak objects into existence,” creating things like furniture in as little as five minutes.


A robotic arm builds a lattice-like stool after hearing the prompt “I want a simple stool,” demonstrating how the Speech-to-Reality system translates speech into real-time fabrication.
Image: Alexander Kyaw
With the Speech-to-Reality system, a robotic arm mounted on a table is able to receive spoken input from a human, such as: “I want a simple stool,” and then construct the objects out of modular components. To date, the researchers have used the system to create stools, shelves, chairs, a small table, and even decorative items such as a dog statue.
“We’re connecting natural language processing, 3D generative AI and robotic assembly,” says Alexander Htet Kyaw, an MIT graduate student and Morningside Academy for Design (MAD) Fellow. “These are rapidly advancing areas of research that haven’t been brought together before in a way that you can actually make physical objects just from a simple speech prompt.”


Examples of objects — such as stools, tables, and decorative forms — constructed by a robotic arm in response to voice commands like “a shelf with two tiers” and “I want a tall dog.”
Image: Alexander Kyaw
The idea started when Kyaw – a graduate student in the Department of Architecture and the Department of Electrical Engineering and Computer Science – took Professor Neil Gershenfeld’s course, “How to Make Almost Anything.” In that class, he built the Speech-to-Reality system. He continued working on the project at the MIT Center for Bits and Atoms (CBA), directed by Neil Gershenfeld, collaborating with graduate students Se Hwan Jeon of mechanical engineering and Miana Smith of CBA.
The Speech-to-Reality system begins with speech recognition that processes the user’s request using a large language model, followed by 3D generative AI that creates a digital mesh representation of the object, and a voxelization algorithm that breaks down the 3D mesh into assembly components.
After that, geometric processing modifies the AI-generated assembly to account for fabrication and physical constraints associated with the real world, such as the number of components, overhangs, and connectivity of the geometry. This is followed by creation of a feasible assembly sequence and automated path planning for the robotic arm to assemble physical objects from user prompts.
By leveraging natural language, the system makes design and manufacturing more accessible to people without expertise in 3D modeling or robotic programming. And, unlike 3D printing, which can take hours or days, this system builds within minutes.
“This project is an interface between humans, AI, and robots to co-create the world around us,” Kyaw says. “Imagine a scenario where you say ‘I want a chair,’ and within five minutes a physical chair materializes in front of you.”
The team has immediate plans to improve the weight-bearing capability of the furniture by changing the means of connecting the cubes from magnets to more robust connections.
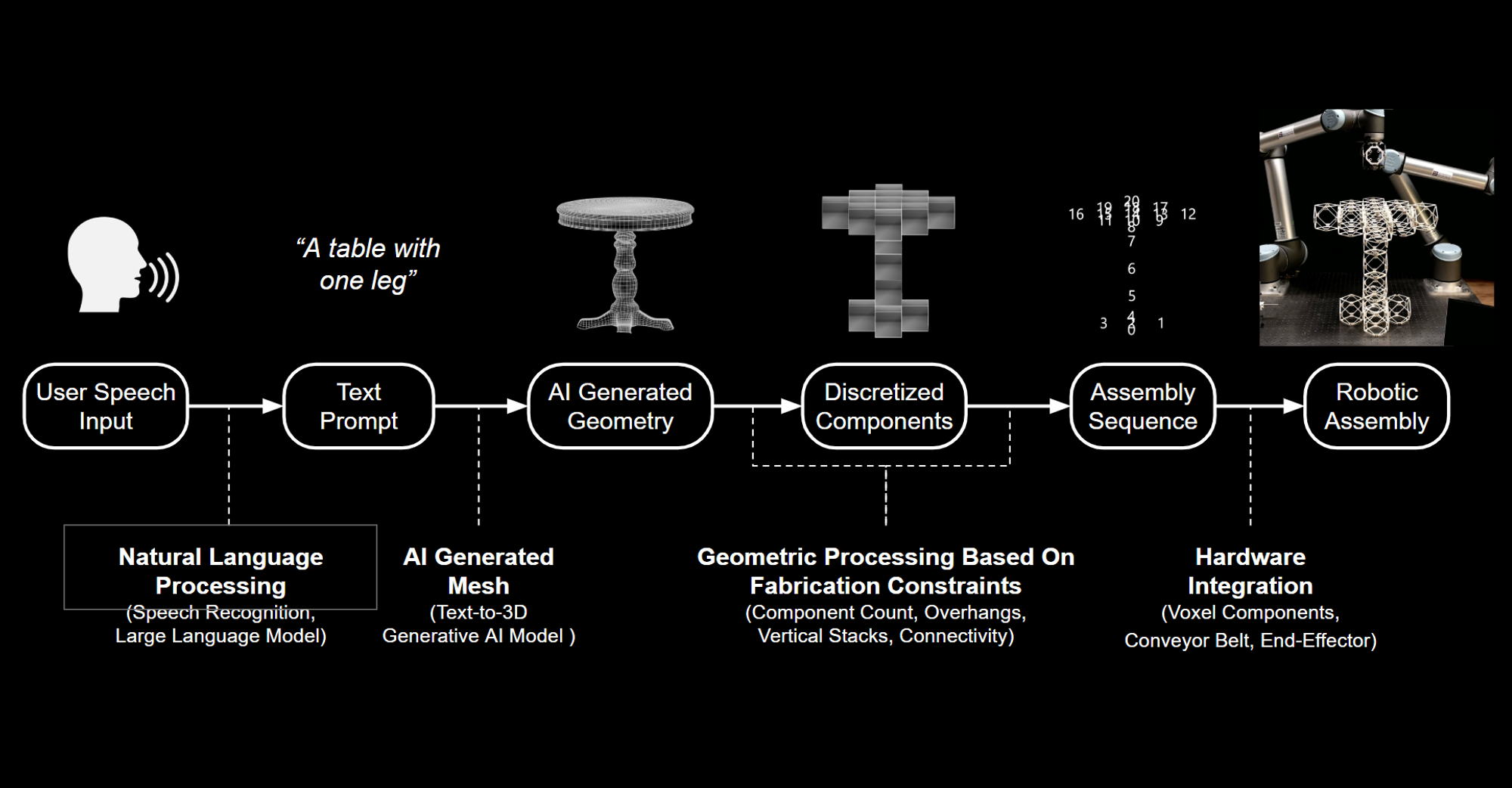

Workflow diagram of MIT’s Speech-to-Reality system, which combines natural-language processing, generative AI, and robotic assembly to turn spoken prompts into fabricated objects within minutes.
Image: Alexander Kyaw
“We’ve also developed pipelines for converting voxel structures into feasible assembly sequences for small, distributed mobile robots, which could help translate this work to structures at any size scale,” Smith says.
The purpose of using modular components is to eliminate the waste that goes into making physical objects by disassembling and then reassembling them into something different, for instance turning a sofa into a bed when you no longer need the sofa.
Because Kyaw also has experience using gesture recognition and augmented reality to interact with robots in the fabrication process, he is currently working on incorporating both speech and gestural control into the Speech-to-Reality system.
Leaning into his memories of the replicator in the “Star Trek” franchise and the robots in the animated film, “Big Hero Six,” Kyaw explains his vision.
“I want to increase access for people to make physical objects in a fast, accessible and sustainable manner,” he says. “I’m working towards a future where the very essence of matter is truly in your control. One where reality can be generated on demand.”
The team will present their paper “Speech to Reality: On-Demand Production using Natural Language, 3D Generative AI, and Discrete Robotic Assembly” Speech to Reality: On-Demand Production using Natural Language, 3D Generative AI, and Discrete Robotic Assembly at the Association for Computing Machinery (ACM) Symposium on Computational Fabrication (SCF ’25) to be held at MIT Nov. 21, 2025.
Apr 9, 2025

May 2, 2024
Oct 4, 2024



